Simple two-dimensional map with Gaussian likelihood
A model \(f:\mathbb{R}^{2}\to \mathbb{R}^{2}\) is chosen in this experiment having the closed-form expression
Observations \(\boldsymbol{x}\) are generated as
where \(\boldsymbol{x}_{0} \sim \mathcal{N}(0,\boldsymbol I_2)\) and \(\odot\) is the Hadamard product. We set the true model parameters at \(\boldsymbol{z}^{*} = (3, 5)^T\), with output \(\boldsymbol{x}^{*} = f(\boldsymbol z^{*})=(7.99, -2.59)^{T}\), and simulate 50 sets of observations from (3). The likelihood of \(\boldsymbol z\) given \(\boldsymbol{x}\) is assumed Gaussian and we adopt a noninformative uniform prior \(p(\boldsymbol z)\). We allocate a budget of \(4\times4=16\) model solutions to the pre-grid and use the rest to adaptively calibrate \(\widehat{f}\) using 2 samples every 1000 normalizing flow iterations.
Results in terms of loss profile, variational approximation and posterior predictive distribution are shown in Fig. 1.
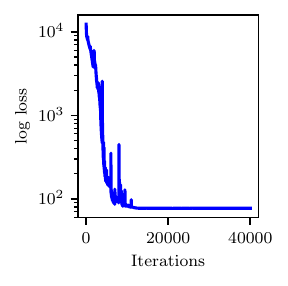
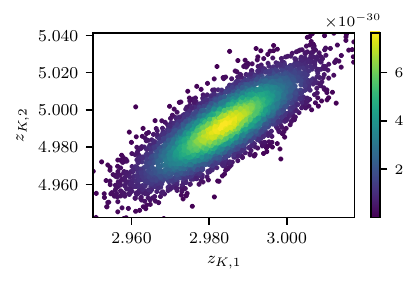
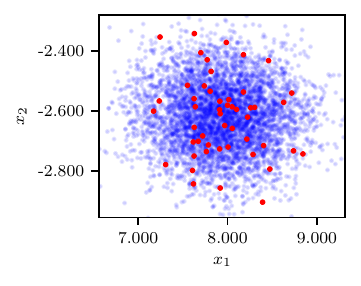
Fig. 1 Results from the trivial model. Loss profile (top), posterior samples (center) and posterior predictive distribution (bottom).
An implementation of this model can be found below.
def trivial_example(self):
if "it" in os.environ:
max_it = int(os.environ["it"])
max_pre = 1000
else:
max_it = 25001
max_pre = 40000
print('')
print('--- TEST 1: TRIVIAL FUNCTION - NOFAS')
print('')
# Import trivial model
from linfa.models.trivial_models import Trivial
exp = experiment()
exp.name = "trivial"
exp.flow_type = 'realnvp' # str: Type of flow (default 'realnvp')
exp.n_blocks = 5 # int: Number of layers (default 5)
exp.hidden_size = 100 # int: Hidden layer size for MADE in each layer (default 100)
exp.n_hidden = 1 # int: Number of hidden layers in each MADE (default 1)
exp.activation_fn = 'relu' # str: Actication function used (default 'relu')
exp.input_order = 'sequential' # str: Input order for create_mask (default 'sequential')
exp.batch_norm_order = True # bool: Order to decide if batch_norm is used
exp.save_interval = 5000 # int: How often to sample from normalizing flow
exp.input_size = 2 # int: Dimensionality of input (default 2)
exp.batch_size = 200 # int: Number of samples generated (default 100)
exp.true_data_num = 2 # double: number of true model evaluated (default 2)
# exp.n_iter = 25001
exp.n_iter = max_it # int: Number of iterations (default 25001)
exp.lr = 0.002 # float: Learning rate (default 0.003)
exp.lr_decay = 0.9999 # float: Learning rate decay (default 0.9999)
exp.log_interval = 10 # int: How often to show loss stat (default 10)
exp.run_nofas = True
exp.surr_pre_it = max_pre #:int: Number of pre-training iterations for surrogate model
exp.surr_upd_it = 6000 #:int: Number of iterations for the surrogate model update
exp.annealing = False
exp.calibrate_interval = 1000 # int: How often to update surrogate model (default 1000)
exp.budget = 64 # int: Total number of true model evaluation
exp.surr_folder = "./"
exp.use_new_surr = True
exp.output_dir = './results/' + exp.name
exp.log_file = 'log.txt'
exp.seed = random.randint(0, 10 ** 9) # int: Random seed used
exp.n_sample = 5000 # int: Batch size to generate final results/plots
exp.no_cuda = True # Running on CPU by default but tested on CUDA
exp.optimizer = 'RMSprop'
exp.lr_scheduler = 'ExponentialLR'
exp.device = torch.device('cuda:0' if torch.cuda.is_available() and not exp.no_cuda else 'cpu')
# Define transformation
# One list for each variable
trsf_info = [['identity',0,0,0,0],
['identity',0,0,0,0]]
trsf = Transformation(trsf_info)
exp.transform = trsf
# Define model
model = Trivial(device=exp.device)
exp.model = model
# Get data
res_path = os.path.abspath(os.path.join(os.path.dirname(linfa.__file__), os.pardir))
model.data = np.loadtxt(res_path + '/resource/data/data_trivial.txt')
# Define surrogate
exp.surrogate = Surrogate(exp.name, lambda x: model.solve_t(trsf.forward(x)), 2, 2,
model_folder=exp.surr_folder, limits=[[0, 6], [0, 6]],
memory_len=20, device=exp.device)
surr_filename = exp.surr_folder + exp.name
if exp.use_new_surr or (not os.path.isfile(surr_filename + ".sur")) or (not os.path.isfile(surr_filename + ".npz")):
print("Warning: Surrogate model files: {0}.npz and {0}.npz could not be found. ".format(surr_filename))
# 4 samples for each dimension: pre-grid size = 16
exp.surrogate.gen_grid(gridnum=4)
exp.surrogate.pre_train(exp.surr_pre_it, 0.03, 0.9999, 500, store=True)
# Load the surrogate
exp.surrogate.surrogate_load()
# Define log density
def log_density(x, model, surrogate, transform):
# x contains the original, untransformed inputs
# Compute transformation log Jacobian
adjust = transform.compute_log_jacob_func(x)
# Eval model output
stds = torch.abs(model.solve_t(model.defParam)) * model.stdRatio
Data = torch.tensor(model.data).to(exp.device)
if surrogate:
modelOut = exp.surrogate.forward(x)
else:
modelOut = model.solve_t(transform.forward(x))
# Eval LL
ll1 = -0.5 * np.prod(model.data.shape) * np.log(2.0 * np.pi)
ll2 = (-0.5 * model.data.shape[1] * torch.log(torch.prod(stds))).item()
ll3 = 0.0
for i in range(2):
ll3 += - 0.5 * torch.sum(((modelOut[:, i].unsqueeze(1) - Data[i, :].unsqueeze(0)) / stds[0, i]) ** 2, dim=1)
negLL = -(ll1 + ll2 + ll3)
# Return LL
return -negLL.reshape(x.size(0), 1) + adjust
# Assign log-density model
exp.model_logdensity = lambda x: log_density(x, model, exp.surrogate, trsf)
# Run VI
exp.run()